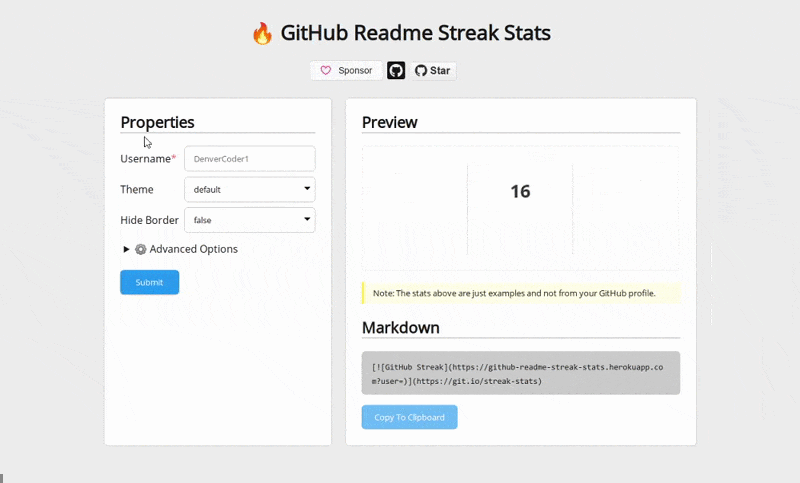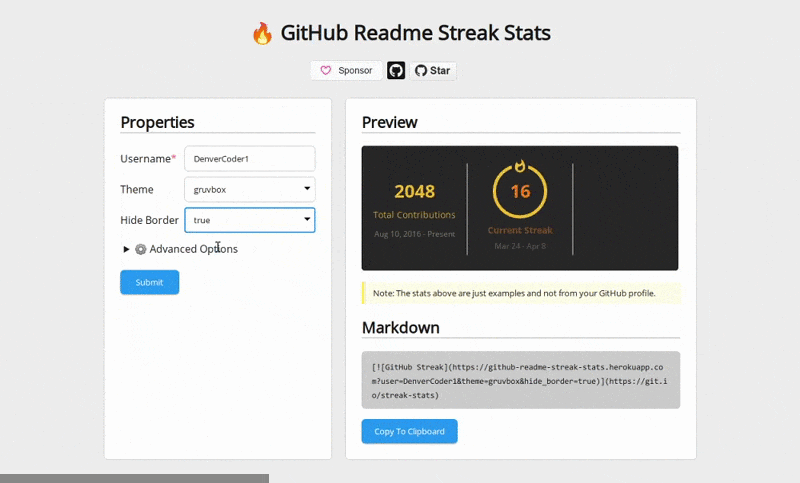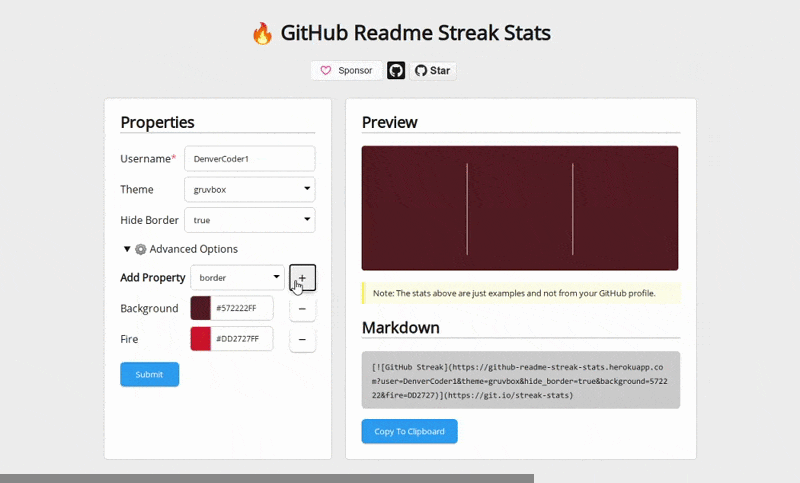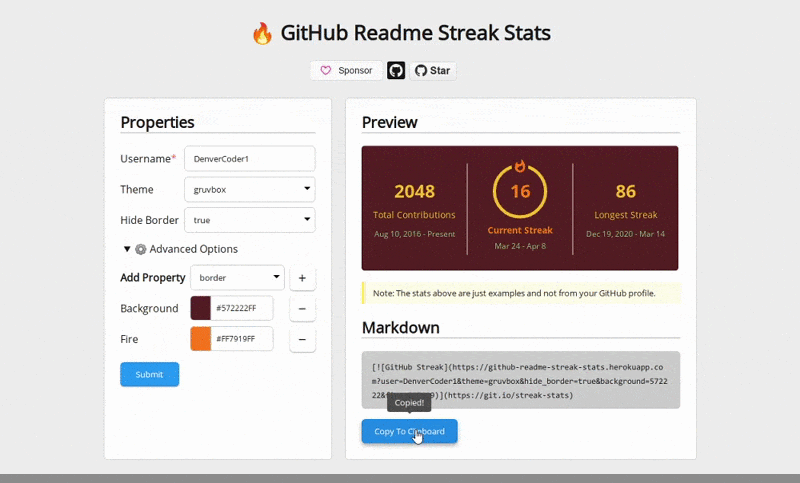
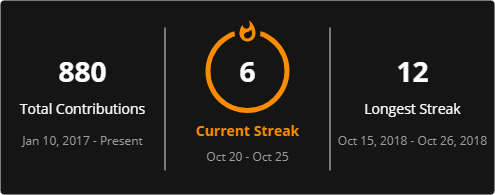
Contextmap generates documentation by scanning your code.
The configuration depends on your project’s programming language and framework.
In your configurations you need to include the scan-key. This is needed to uniquely identify your organization’s account.
When you login you will find this key under “Administration > Scan”.
Most of the scanning happens at compile-time for instance the REST API, entities, markdown, etc. these can be
extracted from the code. However, some things are only known at runtime, for instance Spring beans, config-server settings, etc.
Therefor to run a complete scan of the code you should configure both the compile-time plugin and runtime dependency.
To configure compile-time scanning of your project, add the following plugin
to your pom.xml file. Afterwards you can run the compile-time scan either manually, and/or configure
your CI/CD pipeline to run the scan.
The command to run the compile-time scan is “mvn contextmap:scan“.
Make sure to run this command with the root directory of your project as current directory.
<build>
<plugins>
<plugin>
<groupId>io.contextmap</groupId>
<artifactId>java-spring-compiletime</artifactId>
<version>2.7.0</version>
<configuration>
<key>PLACE_KEY_HERE</key>
</configuration>
</plugin>
</plugins>
</build>
✔️ We highly recommend to modify your CI/CD pipeline to include the contextmap scan.
This way your documentation will be automatically kept up to date.
For multi-module maven projects, the plugin needs to be added only to the root’s pom.xml file. That way all
child-modules will also be scanned. In this case an additional configuration property is needed to ensure all modules
are linked to the same component.
The configuration will look like this:
<build>
<plugins>
<plugin>
<groupId>io.contextmap</groupId>
<artifactId>java-spring-compiletime</artifactId>
<version>2.7.0</version>
<configuration>
<key>PLACE_KEY_HERE</key>
<multiModuleComponentName>COMPONENT_NAME</multiModuleComponentName>
</configuration>
</plugin>
</plugins>
</build>
To configure the runtime scanning of your project, add the following dependency to your pom.xml file.
The runtime scan will only happen once at startup of your project.
<dependencies>
<dependency>
<groupId>io.contextmap</groupId>
<artifactId>java-spring-runtime</artifactId>
<version>2.7.0</version>
</dependency>
</dependencies>
By default the scan at startup is disabled. To enable it and to define the necessary key, add the following
to your configuration file (for instance the application.properties file)
contextmap.key=PLACE_KEY_HERE
contextmap.enabled=true
✔️ If you have multiple environments, such as development, test, production, etc. then you want to make
sure to only configure the runtime scan on one environment. This way you will have a consistent view
of a single environment.
For multi-module maven projects, the dependency needs to be added in the module which is used to run the project.
(i.e. which contains the executed main method).
An additional property is required to indicate that the runtime scan needs to be added to a multi-module project.
The configuration will look like this:
contextmap.key=PLACE_KEY_HERE
contextmap.enabled=true
contextmap.scan.multi-module-component-name=COMPONENT_NAME
Your code already contains lots of knowledge and information, which contextmap scans as-is.
But sometimes you might want to give a little nudge to your documentation, to emphasize or rephrase something.
We have foreseen a library with custom annotations that can be used to achieve this.
To do so, add the following dependency to your pom.xml file.
<dependencies>
<dependency>
<groupId>io.contextmap</groupId>
<artifactId>java-annotations</artifactId>
<version>2.7.0</version>
</dependency>
</dependencies>
You can read more below on how to use these custom annotations.
We do recommend to limit the use of custom annotations to only those cases where it really helps to improve knowledge sharing.
If you have multiple environments, then you can document which version is deployed to which environment.
This allows you to see deployments in the releases overview of your components.
To achieve this, add the following command to your deployment workflow “mvn contextmap:deployment -Dversion=VERSION -Denvironment=ENVIRONMENT“.
The version and environment parameters are to be filled in by your workflow.
One additional configuration setting is required when using the Community Edition, namely the host running the container.
This should be the same backend url as the environment variable configured on the Docker container.
Add the following host-property to the compile-time configuration.
<build>
<plugins>
<plugin>
<groupId>io.contextmap</groupId>
<artifactId>java-spring-compiletime</artifactId>
<version>2.7.0</version>
<configuration>
...
<host>BACKEND_URL</host>
...
</configuration>
</plugin>
</plugins>
</build>
Add the following host-property for the runtime configuration.
contextmap.host=BACKEND_URL
✔️ Note you can use automatic property expansion to inject Maven properties as Spring properties.
Any framework which uses typescript can be scanned, for instance Angular, React, etc.
Also note that with the help of @babel/plugin-proposal-decorators you can also configure a non-typescript pure javascript project.
To configure compile-time scanning of your project, add the following dev-dependency to your package.json file.
Afterwards you can run the compile-time scan either manually, and/or configure your CI/CD pipeline to run the scan.
The command to run the compile-time scan is “npm run contextmap:scan“.
"scripts": {
"contextmap:scan": "node node_modules/@contextmap/typescript-compiletime/cli.js"
},
"devDependencies": {
"@contextmap/typescript-compiletime": "^1.9.0",
},
"contextmap": {
"key": "PLACE_KEY_HERE"
}
✔️ We highly recommend to modify your CI/CD pipeline to include the contextmap scan.
This way your documentation will be automatically kept up to date.
Instead of configuring the key as a property, you can also add it as argument to the script via --key=PLACE_KEY_HERE. This
way, you can for instance refer to an environment variable if needed.
Your code already contains lots of knowledge and information, which contextmap scans as-is.
But sometimes you might want to give a little nudge to your documentation, to emphasize or rephrase something.
We have foreseen a package with custom decorators that can be used to achieve this.
To do so, add the following dependency to your package.json file.
"dependencies": {
"@contextmap/typescript-decorators": "^1.2.0"
}
If you have multiple environments, then you can document which version is deployed to which environment.
This allows you to see deployments in the releases overview of your components.
To achieve this, add the following command to your deployment workflow “npm run contextmap:deployment -- --version=VERSION --environment=ENVIRONMENT“.
The version and environment parameters are to be filled in by your workflow.
"scripts": {
"contextmap:deployment": "node node_modules/@contextmap/typescript-compiletime/deployment.js"
}
One additional configuration setting is required when using the Community Edition, namely the host running the container.
This should be the same backend url as the environment variable configured on the Docker container.
Either the following host-property should be added to the package.json file.
"contextmap": {
...
"host": "BACKEND_URL",
...
}
Or you can also pass the property as parameter using npm run contextmap:your-command -- --host=BACKEND_URL.
The properties are scanned at compile-time.
The overview of a component contains the following details:
- System name is based on the property
contextmap.scan.system-name in your .properties file or .yml file,
if that’s not available then it falls back to the property systemName from the compile-time plugin’s configuration in the pom.xml file,
if that’s not available then it falls back to a default value i.e. “Other”
- Component name is based on the property
contextmap.scan.component-name in your .properties file or .yml file,
if that’s not available then it falls back to the property spring.application.name in your .properties file or .yml file,
if that’s not available then it falls back to the name in the pom.xml
- Component aliases are based on the property
contextmap.scan.component-aliases in your .properties file or .yml file.
This is a comma-separated list of aliases used for the component. You can use this for example when you have an old name and new name for the same component,
or when you have a human-readable name and technical name used during service discovery. (you don’t need to include the component’s name in the list of aliases)
- Domain vision statement is based on the description in the pom.xml
- Technology is based on the dependencies in the pom.xml
- Team is based on the name of the first developer in the pom.xml
- Team’s organization is based on the organization of the first developer in the pom.xml
- Team’s email is based on the email of the first developer in the pom.xml
- Bytes of code is determined by scanning the files in your source folder, counting the filesizes
- Languages are determined by scanning the files in your source folder, and looking at the filenames
- Version is based on the version in the pom.xml
- Url issue management is based on the url from issueManagement’s url in the pom.xml
- Url source code is based on the remote origin from git
- Url for external documentation is based on the url in the pom.xml
- Url buid pipeline is based on the url from ciManagement’s url in the pom.xml
- Component type is based on the property
contextmap.scan.component-type in your .properties file or .yml file,
its value can be MICROSERVICE, MICROFRONTEND, GATEWAY or LIBRARY.
If not available, then it falls back to the default value MICROSERVICE.
If you want to extend the overview and include custom information, then add a property
contextmap.scan.overview-decision-record in your .properties file or .yml file with the filename of the markdown file
which needs to be included.
Domain entities are scanned at compile-time based on any of the following annotations:
- @Entity (javax.persistence.Entity)
- @MappedSuperclass (javax.persistence.MappedSuperclass)
- @Document (org.springframework.data.mongodb.core.mapping.Document,
org.springframework.data.elasticsearch.annotations.Document,
org.springframework.data.couchbase.core.mapping.Document,
com.microsoft.azure.spring.data.cosmosdb.core.mapping.Document)
- @SolrDocument (org.springframework.data.solr.core.mapping.SolrDocument)
- @RedisHash (org.springframework.data.redis.core.RedisHash)
- @Table (org.springframework.data.cassandra.core.mapping.Table)
- @Node (org.springframework.data.neo4j.core.schema.Node)
- @Container (com.azure.spring.data.cosmos.core.mapping.Container)
- @ContextAggregateRoot (io.contextmap.annotations.ContextAggregateRoot)
- @ContextEntity (io.contextmap.annotations.ContextEntity)
For example:
// For example when using JPA
@Entity
public class Order {
}
// For example, when a class is considered part of the domain
// even when it is not necessarily persisted
@ContextEntity
public class Order {
}
The following annotations will identify an entity as aggregate root:
- @ContextAggregateRoot (io.contextmap.annotations.ContextAggregateRoot)
- @Document (org.springframework.data.mongodb.core.mapping.Document,
org.springframework.data.elasticsearch.annotations.Document,
org.springframework.data.couchbase.core.mapping.Document,
com.microsoft.azure.spring.data.cosmosdb.core.mapping.Document)
- @SolrDocument (org.springframework.data.solr.core.mapping.SolrDocument)
- @Container (com.azure.spring.data.cosmos.core.mapping.Container)
For example:
@Entity
@ContextAggregateRoot
public class Order {
}
The custom annotation @ContextSoftLink can be used to identify a soft-link between entities.
This can be used to link entities from the same component, but also between different components.
Use this annotation to document otherwise hidden dependencies between entities.
For example to link to an entity in the same component:
@Entity
public class ProductReadModel {
@ContextSoftLink(entity = Product.class)
private UUID id;
}
For example to link to an entity in another component:
@Entity
public class OrderItem {
@ContextSoftLink(component = "inventory-service", entityName = "Product")
private UUID productId;
}
The published REST API is scanned at compile-time.
The following annotations will identify a class as a published REST API:
- @RestController (org.springframework.web.bind.annotation.RestController)
- @Controller (org.springframework.stereotype.Controller)
Any method included in such a class with one of the following annotations, is seen as a published endpoint
- @GetMapping (org.springframework.web.bind.annotation.GetMapping)
- @PostMappping (org.springframework.web.bind.annotation.PostMapping)
- @PutMapping (org.springframework.web.bind.annotation.PutMapping)
- @DeleteMapping (org.springframework.web.bind.annotation.DeleteMapping)
- @PatchMapping (org.springframework.web.bind.annotation.PatchMapping)
- @RequestMapping (org.springframework.web.bind.annotation.RequestMapping)
REST API’s are grouped per class in which they are defined. By default the class’ name will be used as title for the group.
You could annotate the class with any of the following annotations. These provide attributes to customize the name and description
which are displayed for the group of REST API’s.
- Swagger’s @Tag (io.swagger.v3.oas.annotations.tags.Tag)
- Swagger’s @Api (io.swagger.annotations.Api)
- Custom annotation @ContextRestApi (io.contextmap.annotations.rest.ContextRestApi)
Methods can be documented by any of the following annotations. This way a description can be added to the endpoint methods.
- Swagger’s @Operation (io.swagger.v3.oas.annotations.Operation)
- Swagger’s @ApiOperation (io.swagger.annotations.ApiOperation)
- Custom annotation @ContextRestEndpoint (io.contextmap.annotations.rest.ContextRestEndpoint)
A requestbody or responsebody can be documented by any of the following annotations.
- Swagger’s @Schema (io.swagger.v3.oas.annotations.media.Schema) for type and properties documentation
- Swagger’s @ApiModelProperty (io.swagger.annotations.ApiModelProperty) for properties documentation
- Swagger’s @ApiModel (io.swagger.annotations.ApiModel) for type documentation
- Custom annotation @ContextApiProperty (io.contextmap.annotations.ContextApiProperty) for properties documentation
- Custom annotation @ContextApi (io.contextmap.annotations.ContextApi) for type documentation
For example:
// Using custom annotations
@ContextApi(description = "A confirmed order")
public class OrderDto {
@ContextApiProperty(description = "This datetime is in ISO-8601", example = "2021-12-31")
private LocalDateTime createdOn;
}
// Using Swagger annotation
@Schema(description = "A confirmed order")
public class OrderDto {
@Schema(description = "This datetime is in ISO-8601", example = "2021-12-31")
private LocalDateTime createdOn;
}
By default the name of a property’s class is used as its datatype.
Also by default, all possible values of an enum property are included as example.
If no endpoints are found while scanning for annotations, then a scan for Spring REST Docs snippets occurs.
During the build of projects which use Spring REST Docs to document the api, you will need to make sure that
the snippets are generated before scanning for contextmap, i.e. the tests need to have run.
The subscribed REST API is scanned at compile-time.
The synchronous links between components in contextmap are based on the subscribed REST APIs.
The following annotations will identify a class as a subscribed REST API, and as such
create a link between the components. The name attribute of these annotations will be used, to
identify the component.
- @FeignClient (org.springframework.cloud.openfeign.FeignClient)
- @FeignClient (org.springframework.cloud.netflix.feign.FeignClient)
- @LoadBalancerClient (org.springframework.cloud.loadbalancer.annotation.LoadBalancerClient)
- @LoadBalancerClients (org.springframework.cloud.loadbalancer.annotation.LoadBalancerClients)
- @ContextClient (io.contextmap.annotations.client.ContextClient), can be used on class level and method level
The custom annotation @ContextClient can be used to model any dependency, not just REST.
When using Spring Cloud Gateway, the configuration files are scanned to find routes.
Any configured route which has a load balanced uri-property (i.e. starting with “lb://”) will be identified
as a link to another component.
For example:
// Example using feign.
@FeignClient(name = "order-service")
public interface OrderClient {
@GetMapping("/orders")
List<Order> getOrders();
}
// Example using http exchange. This requires the use of custom annotation ContextClient to detect the interface.
// This is an example using the reactive stack, but the servlet stack is also supported.
@ContextClient(name = "order-service")
public interface OrderClient {
@GetExchange("/orders")
Flux<Order> getOrders();
}
Events are scanned at runtime.
The asynchronous links between components in contextmap are based on the events.
Contextmap currently supports scanning events for the following message brokers
- RabbitMQ
- ActiveMQ (JMS)
- Kafka
- Azure EventHub
- Azure ServiceBus
Exchanges on which the scanned component publishes messages are scanned by finding Spring beans of type
- Exchange (org.springframework.amqp.core.Exchange)
- RabbitTemplate (org.springframework.amqp.rabbit.core.RabbitTemplate)
Also logback AMQP appenders are scanned and identified as exchanges.
Queues on which a component subscribes are scanned by finding Spring beans of type
Binding (org.springframework.amqp.core.Binding)
When using Spring Cloud Stream then producers and consumers are scanned.
Queues/Topics on which the scanned component publishes messages are scanned by finding Spring beans of type
- Queue (javax.jms.Queue)
- Topic (javax.jms.Topic)
Queues/Topics on which the scanned component subscribes are scanned by finding beans with methods
annotated with @JmsListener (org.springframework.jms.annotation.JmsListener)
Topics on which the scanned component publishes messages are scanned by finding Spring beans of type
- NewTopic (org.apache.kafka.clients.admin.NewTopic)
- KafkaTemplate (org.springframework.kafka.core.KafkaTemplate)
Topics on which a component subscribes are scanned by finding Spring beans annotated by
KafkaListener (org.springframework.kafka.annotation.KafkaListener)
When using Spring Cloud Stream then producers and consumers are scanned.
When using Spring Cloud Stream then producers and consumers are scanned.
EventHubs on which the scanned component publishes messages are scanned by finding Spring beans of type
- EventHubProducerClient (com.azure.messaging.eventhubs.EventHubProducerClient)
- EventHubProducerAsyncClient (com.azure.messaging.eventhubs.EventHubProducerAsyncClient)
EventHubs on which a component subscribes are scanned by finding Spring beans of type
- EventHubConsumerClient (com.azure.messaging.eventhubs.EventHubConsumerClient)
- EventHubConsumerAsyncClient (com.azure.messaging.eventhubs.EventHubConsumerAsyncClient)
Use the custom annotation @ContextEvent to allow contextmap to identify the payload
(or potentially multiple payloads) of an event which is published.
Any annotation used to document a REST requestbody or responsebody, can also be used to document the payload of an event.
For example:
// For RabbitMQ you can refer to the name of an Exchange or RabbitTemplate registered as Spring Bean,
// or use SpEL to refer to a property, or directly use the name of the exchange
// (Note: only reference a RabbitTemplate Spring Bean, when it's default exchange is configured)
@ContextEvent(publishedBy = "orderCreatedExchange")
public class OrderCreated {
@ContextApiProperty(description = "This datetime is in ISO-8601", example = "2021-12-31")
private LocalDateTime createdOn;
}
// For ActiveMQ you can refer to the name of a Queue or Topic registered as Spring Bean,
// or use SpEL to refer to a property, or directly use the name of the topic/queue
@ContextEvent(publishedBy = "orderCreatedTopic")
public class OrderCreated {
}
// For Kafka you can refer to the name of a Topic or KafkaTemplate registered as Spring Bean,
// or use SpEL to refer to a property, or directly use the name of the topic
// Note: when using Kafka Cloud Stream you can only use a SpEL expression or directly use the name of the topic
@ContextEvent(publishedBy = "orderCreatedTopic")
public class OrderCreated {
}
// Example of referring to a configuration property (e.g. when using Spring Cloud Stream)
@ContextEvent(publishedBy = "${order-created.exchange}")
public class OrderCreated {
}
// Example of referring to the actual name (e.g. when using Spring Cloud Stream)
@ContextEvent(publishedBy = "order-created")
public class OrderCreated {
}
Storages are scanned at runtime.
Contextmap currently supports scanning the following types of storages:
- JDBC databases are scanned by finding Spring beans of type DataSource
(javax.sql.DataSource).
Tables and views for the current schema/catalog of the database are included in the scan.
- MongoDB is scanned by finding Spring beans of type MongoTemplate
(org.springframework.data.mongodb.core.MongoTemplate) and ReactiveMongoTemplate
(org.springframework.data.mongodb.core.ReactiveMongoTemplate)
- CosmosDB is scanned by finding Spring beans of type CosmosTemplate
(com.azure.spring.data.cosmos.core.CosmosTemplate) and ReactiveCosmosTemplate
(com.azure.spring.data.cosmos.core.ReactiveCosmosTemplate)
- Solr is scanned by finding Spring beans of type SolrTemplate
(org.springframework.data.solr.core.SolrTemplate)
- ElasticSearch is scanned by finding Spring beans of type RestHighLevelClient
(org.elasticsearch.client.RestHighLevelClient), if none are detected then bean of type RestClient
(org.elasticsearch.client.RestClient) are scanned
- Caches are scanned by getting the caches from Spring’s CacheManager
(org.springframework.cache.CacheManager)
Furthermore, a custom annotation @ContextStorage (io.contextmap.annotations.storage.ContextStorage)
can be used to symbolize any custom types of storage
// Example of a class responsible for accessing certain files
// ContextMap can not discover this storage because there is no well-defined SpringBean, hence the need for the custom annotation
@ContextStorage(name = "training-sets", type = StorageType.FILE_SYSTEM)
public class TrainingSetData {
}
For JDBC databases the tables and views are documented. For MongoDB the collections are documented, and schema analysis
is done based on the first 100 documents in a collection.
Decision records and other markdown files are scanned at compile-time.
This is done by looking at the source folder and checking the file-extension.
Each file with extension .md, .ad or .adr will be included.
Unmodified files will be ignored. If you modify a file which was previously scanned, then
the next time it is scanned it will be updated.
Note that Mermaid diagrams can be included.
PlantUML diagrams included in your project are scanned at compile-time.
This is done by looking at the source folder and checking the file-extension.
Each file with extension .puml, .iuml or .plantuml will be included.
Unmodified files will be ignored. If you modify a file which was previously scanned, then
the next time it is scanned it will be updated.
The Smetana rendering engine of PlantUML is used. Depending on the diagram, this means you may need to add
an extra configuration line to ensure the diagram is rendered correctly.
@startuml
!pragma layout smetana <-- extra configuration line
@enduml
Features are scanned at compile-time.
This is done by looking at the source folder and checking the file-extension.
Each file with extension .feature, or .story will be included.
Unmodified files will be ignored. If you modify a file which was previously scanned, then
the next time it is scanned it will be updated.
Releases are scanned at compile-time.
All local tags in Git will be included. The commits associated with each tag are also included.
Only the date and the message of a commit is tracked.
Other information (such as the person who made the commit) is not tracked.
Recent commits are scanned at compile-time.
All commits in Git from the last 90 days will be included.
Only the date and the message of a commit is tracked.
Other information (such as the person who made the commit) is not tracked.
The glossary terms are scanned at compile-time.
Use the custom annotation @ContextGlossary to scan for terms to include in your glossary.
For example:
@ContextGlossary("A request to make, supply, or deliver food or goods")
public class Order {
}
You can specify the name attribute in case the name of the class is not the term you want to use in the glossary.
You can also document any aliases which could be used for the same term.
@ContextGlossary(
value = "A list of goods sent or services provided, with a statement of the sum due for these",
name = "Invoice",
aliases = {"Bill"}
)
public class InvoiceEntity {
}
The tech radar entries are scanned at compile-time.
You typically will want to manage this from a single “architecture governance” project, instead of having contributions from multiple components.
This architecture governance project would require only a single file, namely the pom.xml
To define the tech radar entries, add the following configuration to the plugin inside the pom.xml
<plugin>
<groupId>io.contextmap</groupId>
<artifactId>java-spring-compiletime</artifactId>
<version>2.7.0</version>
<configuration>
<key>PLACE_KEY_HERE</key>
<techRadar>
<entries>
<entry>
<label>Name of the entry, e.g. GitHub Actions</label>
<link>Link to external website (optional), e.g. https://www.github.com</link>
<description>A description of the entry (optional)</description>
<quadrant>Either: TOOLS, TECHNIQUES, FRAMEWORKS, LANGUAGES (optional, default is TOOLS)</quadrant>
<ring>Either: ADOPT, TRIAL, ASSESS, HOLD (optional, default is HOLD)</ring>
<movement>Either: NONE, UP, DOWN (optional, default is NONE)</movement>
</entry>
</entries>
</techRadar>
</configuration>
</plugin>
The business capabilities of a component are scanned at compile-time.
There are 3 ways to document capabilities:
- using pom.xml
- using properties (*.properties or *.yml)
- using annotations
Example when using pom.xml:
<plugin>
<groupId>io.contextmap</groupId>
<artifactId>java-spring-compiletime</artifactId>
<configuration>
...
<capabilities>
<capability>Inventory management</capability>
<capability>Legal and compliance</capability>
</capabilities>
...
</configuration>
</plugin>
Example when using properties:
# Specify the capabilities as a comma-separated list
# e.g. in application.properties
contextmap.scan.capabilities=Inventory management, Legal and compliance
# e.g. in application.yml
contextmap:
scan:
capabilities: Inventory management, Legal and compliance
Example when using annotations:
// When specifying a single capability you can use
@ContextCapability("Legal and compliance")
public class ComplaintsApplication {
}
// Or when specifying multiple capabilities you can use
@ContextCapabilities({
@ContextCapability("Inventory management"),
@ContextCapability("Legal and compliance")
})
public class InventoryApplication {
}
The actors of a component are scanned at compile-time.
Use the custom annotation @ContextActor to indicate that a certain actor uses the component.
For example:
@ContextActor("Helpdesk")
public class OrderApplication {
}
Or use @ContextActors, to link multiple actors at once.
For example:
@ContextActors({
@ContextActor("Data Scientist"),
@ContextActor("Data Engineer")
})
public class DataAnalysisApplication {
}
Documenting exemplary code happens at compile time.
Use the custom annotation @ContextExemplar to indicate that a certain file or class should be considered the starting point of the exemplary code.
For example:
@ContextExemplar(
title = "Oracle & RabbitMQ Testcontainer",
description = "This integration test uses two testcontainers (RabbitMQ and Oracle) to simulate the production environment perfectly.",
tags = { "testcontainer", "oracle", "rabbitmq" }
)
public class OrderPlacementContainerTest {
}
The properties are scanned at compile-time.
The overview of a component contains the following details:
- System name is based on the property
contextmap.scan.systemName from the package.json file, or you can override this by passing it as argument systemName, if neither are defined then it falls back to a default value i.e. “Other”
- Component name is based on the property
name from the package.json file, or you can override this by passing it as argument componentName
- Component aliases are based on the property
contextmap.scan.aliases from the package.json file.
This is an array of aliases used for the component. You can use this for example when you have an old name and new name for the same component,
or when you have a human-readable name and technical name. (you don’t need to include the component’s name in the list of aliases)
- Domain vision statement is based on the
description from the package.json file
- Technology is based on the
dependencies from the package.json file
- Team is based on the property
author.name from the package.json file
- Team’s organization is based on the property
contextmap.scan.organization from the package.json file
- Team’s email is based on the property
author.email from the package.json file
- Bytes of code is determined by scanning the source files, counting the filesizes
- Languages are determined by scanning the source files, and looking at the filenames
- Version is based on the version from the package.json file
- Url issue management is based on the bugs url from the package.json file
- Url source code is based on the repository url from the package.json file
- Url for external documentation is based on the homepage from the package.json file
- Component type is based on the property
contextmap.scan.componentType from the package.json file,
its value can be MICROSERVICE, MICROFRONTEND, GATEWAY or LIBRARY
if not available then it falls back to the default value MICROFRONTEND
If you want to extend the overview and include custom information, then add a property
contextmap.scan.overviewDecisionRecord to the package.json file, with the filename of the markdown file
which needs to be included.
The subscribed REST API is scanned at compile-time.
The synchronous links between components in contextmap are based on the subscribed REST APIs.
Use the custom decorator @ContextClient to identify a dependency to another component.
For example:
@ContextClient('webshop-site-gateway')
export class GatewayHttpService {
}
Decision records and other markdown files are scanned at compile-time.
This is done by looking at the source folder and checking the file-extension.
Each file with extension .md, .ad or .adr will be included.
Unmodified files will be ignored. If you modify a file which was previously scanned, then
the next time it is scanned it will be updated.
Note that Mermaid diagrams can be included.
Features are scanned at compile-time.
This is done by looking at the source folder and checking the file-extension.
Each file with extension .feature, or .story will be included.
Unmodified files will be ignored. If you modify a file which was previously scanned, then
the next time it is scanned it will be updated.
Releases are scanned at compile-time.
All local tags in Git will be included. The commits associated with each tag are also included.
Only the date and the message of a commit is tracked.
Other information (such as the person who made the commit) is not tracked.
Recent commits are scanned at compile-time.
All commits in Git from the last 90 days will be included.
Only the date and the message of a commit is tracked.
Other information (such as the person who made the commit) is not tracked.
The glossary terms are scanned at compile-time.
Use the custom decorator @ContextGlossary to scan for terms to include in your glossary.
For example:
@ContextGlossary({ definition: 'A request to make, supply, or deliver food or goods' })
export class Order {
}
You can specify the name attribute in case the name of the class is not the term you want to use in the glossary.
You can also document any aliases which could be used for the same term.
@ContextGlossary({
name: 'Invoice',
definition: 'A list of goods sent or services provided, with a statement of the sum due for these',
aliases: ['Bill']
})
export class InvoiceEntity {
}
The tech radar entries are scanned at compile-time.
You typically will want to manage this from a single “architecture governance” project, instead of having contributions from multiple components.
This architecture governance project would require only a single file, namely the package.json
To define the tech radar entries, add the following configuration to the contextmap section inside the package.json
"contextmap": {
"key": "PLACE_KEY_HERE",
"techRadar": {
"entries": [
{
"label": "Name of the entry, e.g. GitHub Actions",
"link": "Link to external website (optional), e.g. https://www.github.com</link>",
"description": "A description of the entry (optional)",
"quadrant": "Either: TOOLS, TECHNIQUES, FRAMEWORKS, LANGUAGES (optional, default is TOOLS)",
"ring": "Either: ADOPT, TRIAL, ASSESS, HOLD (optional, default is HOLD)",
"movement": "Either: NONE, UP, DOWN (optional, default is NONE)"
}
]
}
}
The business capabilities of a component are scanned at compile-time.
There are 2 ways to document capabilities:
- using package.json
- using decorators
Example when using package.json:
contextmap: {
scan: {
...
capabilities: ["Inventory management", "Legal and compliance"],
...
}
}
Example when using decorators:
// When specifying a single capability you can use
@ContextCapability("Legal and compliance")
export class ComplaintsAppComponent {
}
// Or when specifying multiple capabilities you can use
@ContextCapabilities(["Inventory management", "Legal and compliance"])
export class InventoryAppComponent {
}
The actors of a component are scanned at compile-time.
Use the custom decorator @ContextActor/@ContextActors to indicate that a certain actor uses the component.
For example:
@ContextActor('Customer')
export class AppComponent {
}
Or in case there are multiple actors:
@ContextActors(['Customer', 'Support'])
export class AppComponent {
}
Documenting exemplary code happens at compile time.
Use the custom decorator @ContextExemplar to indicate that a certain class should be considered the starting point of the exemplary code.
For example:
@ContextExemplar({
title = 'NgRx Action Hygiene',
description = 'Example of good NgRx action hygiene in combination with lazy loaded modules',
tags = {'ngrx'}
})
export class OrderActions {
}







 https://github.com/microsoft/Purview-Custom-Connector-Solution-Accelerator
https://github.com/microsoft/Purview-Custom-Connector-Solution-Accelerator